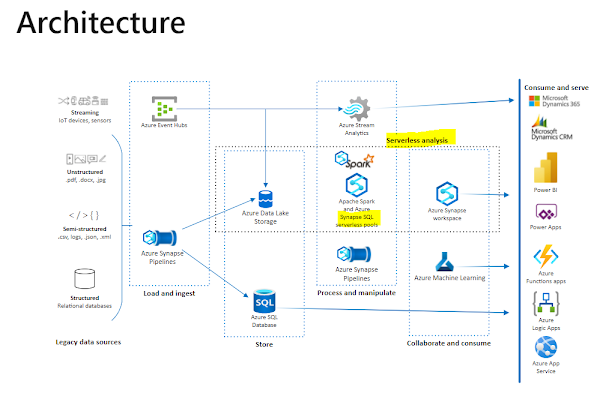
Does Azure Synapse combine all the bestSQLTechnologies used in company data warehouseSparkTechnologies to analyze big dataPipelinesData alliance, ETL/ELT, and deep integration with other Azure Services such as power BI? CosmosDBAndAzureML.
Azure SQL provides two types of SQL services.
- Serverless SQL Pool
- Dedicated SQL pool
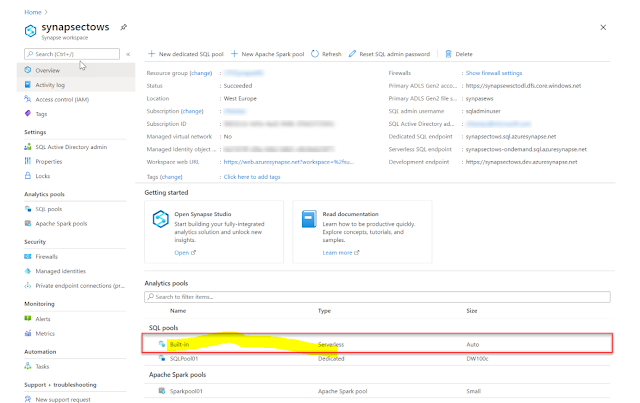
Serverless SQL Pool
If it is uncertain how many resources you have and unpredictable, you might prefer a serverless model where you don’t need to invest in Infra.
You can use a Serverless SQL Pool to query data in the Azure Data Lake (Parquet or Delta Lake, delimited texts formats), Cosmos DB or Dataverse.
Data can be ingested electronically before being accessed. Infra setup is necessary and pays on a per-use basis.
Use the always available, serverless SQL endpoint for unplanned or bursty workloads.
This means that there are no charges for resources you reserve, but only for data, you query. This means that there is no charge for resources you relieve, but only for the data, your question.
You can access your data utilizing the following:
* Use the familiar T-SQL syntax for querying data in place without copying or loading it into a specialized store.
* The T-SQL interface provides integrated connectivity that allows for various business intelligence tools and ad-hoc queries.
Useful for the following situations:
Connect quickly to Data Lake to query data and gain insights. No need to ingest it to Datawarehouse storage.
- This allows you to create a Logical Data Warehouse without having to move any data. It is very simple and needs no maintenance.
- Data can also be transformed using Tsql to load it into Synapse DW or SQL database.
Also Read: How To Become Azure Data Scientist Associate?
Different roles can benefit from it. This is how it works.
Data Engineers: This service allows users to investigate the lake and change and provide data. It also analyses data transformation processes.
Data Analysts: You can observe data and spark external records created by Data Scientists/Data Engineers.
Data scientists are possible to quickly analyze the structure and contents of data in the lake.
BI specialists can promptly create Power BI reports from data in the Spark and lake tables.
Each Azure Synapse Analytics workspace includes a serverless SQL pool, which you can use for querying data in the lake.